How do we cut a six-figure Amazon Web Services (AWS) bill? This has been the question I’ve been wrestling with since 2013. When I was first asked to tackle this challenge, we were running hundreds of Elastic Cloud Compute (EC2) instances, hundreds of queues in Simple Queueing Service (SQS), dozens of database instances in Relational Database Service (RDS), hundreds of NoSQL tables in DynamoDB, and about another dozen AWS components that we were leveraging regularly. At one point, we were considered one of the few organizations that was using almost every AWS cloud service in existence. It makes sense that a hefty price tag was attached to this amount of utilization.
The thing about startups is that rapid progress and time-to-market are at the top of everyone’s priority list. The challenge is not to let your infrastructure costs become excessive. In late 2013 we saw that we were letting our costs run rampant on the systems side. This was when I volunteered to drive the cost optimization project. I was already well acquainted with most of the AWS services we were leveraging but finding inefficiencies and optimizing was not something I’d done before in this area. The best way to tackle a new kind of problem is by understanding the current situation. To that end I started by evaluating our current cost breakdown in a visualization tool called Teevity.
What I learned from Teevity was pretty hard to believe. Among the many things that seemed too expensive for our organization, the first one that really stuck out to me was queueing.
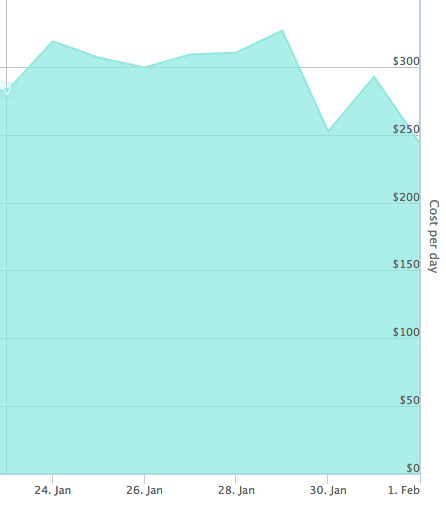
We had over 200 managed queues set up in AWS SQS and were spending on average $280/day just on queueing. My estimate was that our I/O was approximately 100 million messages daily. About two-thirds of these queues had low utilization because they were set up for our non-production environments. The existence of queues with little utilization has almost no associated cost. An idle SQS queue essentially exists free of charge. These were not going to help lower costs.
As I brushed up on my SQS documentation and monitored usage patterns in AWS CloudWatch (the de facto monitoring system tied into all AWS services) and the SQS console itself, I realized that we were doing something bad. We weren’t using batching. More accurately, we weren’t using batching enough.
You see, we are a Java/PHP house. Most of our core platform services are pure Java and leverage AWS SDK for Java when talking to any AWS managed service. We also use a lot of Apache Camel for message routing within and without our applications. While integrating his application with AWS SQS, one of our architects wrote a multi-threaded version of Camel’s AWS SQS component that allowed us to increase SQS I/O throughput (this is now unnecessary as Camel’s AWS SQS component can now handle concurrent polling threads natively) and leverage receive (consumer) batching. This helped us move data in and out of SQS much more rapidly as well as save a bit of money. Unfortunately we were unable to take advantage of all the cost savings available to us until I found that AWS SDK for Java had an AWS SQS buffered client that included implicit producer (send) buffering and auto-batching.
The capability of buffering messages on the SQS client is great because the client is one of the first/last points of contact with the SQS API (first on receive, last on send). This is advantageous because the client can be responsible for minimizing API I/O (and in turn cost) and at a higher level, the application can be less coupled to how it communicates with it’s various queues. When we switched to the native buffered AWS SQS client in each application, it immediately produced cost savings. When an SQS producer would request a message to be sent to a certain queue, the AWS SQS client would hold the message for a few hundred milliseconds (configurable) while waiting for additional requests. If no additional requests were received, the message was sent as is. But, if more messages were received within the buffering wait time, a batch was created. This batch would hold up to 10 messages (configurable) and then be sent to the appropriate SQS queue. So instead of hitting the SQS API 10 times, we would only hit it once when the batch was optimally filled. This produced a cost savings of up to 10x (on the sending side) in every application we applied the learning to.
The great thing about the change that made this possible was that the AWS SQS buffered client was a drop-in replacement for the unbuffered client. With our universal usage of Spring Dependency Injection, using a different AWS SQS client was literally a change that consisted of a few lines of code in our in-house SQS Camel library. Even without dependency injection, the scope of the drop-in change is minimal as follows:
// Create the basic SQS async client AmazonSQSAsync sqsAsync=new AmazonSQSAsyncClient(credentials); // Create the buffered client AmazonSQSAsync bufferedSqs = new AmazonSQSBufferedAsyncClient(sqsAsync);
The other change that we applied was to enable Long Polling on most of our queues. Long Polling allows the SQS client to wait up to 20 seconds when polling for new messages for there to actually be messages in the queue. For queues with inconsistent usage patterns (that can sit empty for at least a few seconds at a time), this can eliminate a great deal of API hits that return with no results.
After all the above discussed changes were applied, our overall AWS SQS cost dropped by 4x from $280 to $70/day.
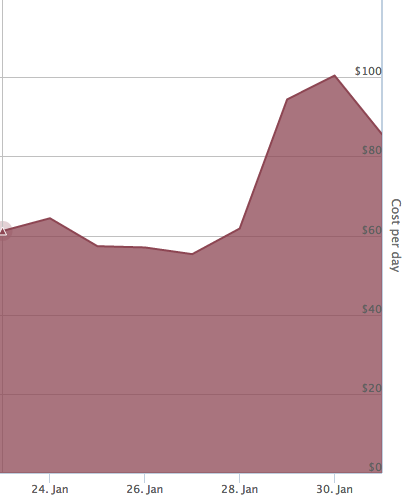
Overall, we learned that sometimes significant cost savings can be had with simple changes to the way we use infrastructure. With the modifications discussed above, none of ours platform functionality was sacrificed, but we were able to cut our costs by 4x. There are more examples of this kind coming up in this series!
In the soon to be released Part 2, I will discuss another simple way to cut AWS costs.